Добрый день. Подскажите за счет чего увеличивается обьем базы данных? База Террасофта находится на отдельном сервере и весит на сегодня порядка 100ГБ.
Версия террасофта - 3.3.1.148
БД - Файерберд
Заранее спасибо, за помощь.
Часто это случается из-за пустого места в таблицах. Необходимо проводить переиндексацию таблиц и выполнять операцию srink на базе SQL. Я так добилась двукратного уменьшения базы.
Как все это правильнее сделать , Вам подробнее может помочь техподдежка.
Кроме этого у меня в базе зависали неудаленные файлы (после того, как объект к которому они были привязаны, удалялись сами файлы из базы не удалялись). Это я вычищала скриптами.
"Бучковский" написал:Подскажите за счет чего увеличивается обьем базы данных
Смотрите размеры таблицы tbl_MailMessages и tbl_Files
Если пользоваться ibexpert, то это меню Services-Database Statistics.
Основной рост базы данных за счет прикрепления писем и хранения файлов в базе данных.
Плюс, как написала Виктория, из-за пустого места в таблицах - подробнее здесь
"Тихенко Виктория" написал:выполнять операцию srink на базе SQL
Для firebird операция shrink не существует. Делается бэкап базы и ее восстановление. В результате свободное место будет реорганизовано.
В процессе администрирования базы данных возникла необходимость определить причину возникновения ошибки. Определенный объём информации импортируется в базу данных, с которым далее пользователи работают. В процессе заполнения определенного набора полей автоматически высчитывалась итоговая сумма в поле «Итого». Но в определённый промежуток времени использования продукта начали появляться ошибки, связанные с несоответствием значения поля «Итого» сумме полей из которых оно вычисляется («Сумма покупки», «Наценка», «Сбор» и т.д.). Так как ошибку не получалось явно повторить, необходимо было разработать механизм для решения данной проблемы.
Естественно самой реальной и первой причиной возникновения такой ошибки приходила идея о сбоях в работе событий полей окна редактирования (то есть значения в полях изменялись, а события данных полей(-я) не срабатывали).
В основу решения было положено создание двух таблиц в базе данных для ведения логов, что происходят с записью набора данных. Первая таблица WindowLog, а вторая TriggerLog.
Первая таблица WindowLog включает в себя поля «Дата создания»(CreatedOn), «Идентификатор записи» (RecordID), «Ответственный» (WindowsUser), «Имя поля породившего событие»(FieldName), «Итого» и поля из которых оно вычисляется («Сумма покупки», «Наценка», «Сбор» и т.д.). Для наполнения таблицы было использованы события невизуального компонента окна dlData: dlDataOnDatasetDataChange, dlDataOnDatasetBeforePost и dlDataOnDatasetAfterPost. В скрипте в событиях была создана функция, которая формировала SQL запрос к таблице WindowLog базы данных с фиксацией информации по указанным полям на момент срабатывания события.
Вторая таблица TriggerLog включает в себя поля «Дата создания»(CreatedOn), «Идентификатор записи» (RecordID), «Состояние» (до изменения записи и после), «SystemUser», «Итого» и поля из которых оно вычисляется («Сумма покупки», «Наценка», «Сбор» и т.д.). Для заполнения данной таблицы был создан триггер на инструкцию UPDATE проблемной таблицы с двумя запросами вставки значений в таблицу. В одном запросе вставлялись значения до изменений, а во втором после.
Запрос №1:
INSERTINTO TriggerLog (*набор полей*) SELECT(*набор полей*) FROM deleted
Запрос №2:
INSERTINTO TriggerLog (*набор полей*) SELECT(*набор полей*) FROM inserted
Результатом использования данного решения на основе анализа таблицы WindowLog было установлено, что срабатывают все события окна редактирования, влияющие на вычисление значения поля «Итого». В процессе использования окна редактирования и после сохранения записи значения поля «Итого» были корректны.
Проанализировав записи в таблице TriggerLog было установлено, что в результате выполнения инструкции UPDATE было внесено некорректное значение. Сопоставив даты создания записей в таблице TriggerLog и WindowLog было установлено, что инструкция UPDATE была вызвана не в результате манипуляций с окном редактирования, а иным источником. На основании поля «SystemUser» таблицы TriggerLog было установлено что изменения были внесены с помощью импортера данных.
Таблицу TriggerLog возможно расширить, добавив в нее поля, которые помогут ускорить процесс обнаружение источника изменений записи базы данных. Список дополнительных полей может выгладять следующим образом: ApplicationName, LoginName, HostName.
PS: Принимаю предложения на доработку вашей конфигурации!!! Для более детальной информации можно связаться по следующему e-mail адресу: !!!
В случае возникновения дополнительных вопрос по теме могу поделиться более детальной информацией.
Многие из нас пользуются бесплатными версиями MS SQL Server, которые, как вы понимаете, имеют ограничение на размер базы данных. Рано или поздно, у Вас появится сообщение примерно такого характера :
Это означает, что вы полностью использовали бесплатно предоставленное вам место.
Как показывает практика, то самой ресурсоемкой таблицей в базе данных является таблица tbl_MassMail, из-за большого количества корреспонденции в базе данных.
Для того, чтоб определить сколько места занимает каждая из таблиц базы данных вы можете использовать скрипт :
/*
** For update free space uncomment follow --, N'TRUE'
*/
Обращаю ваше внимание, что скрипт дает информацию о занимаемом месте каждой таблицей в базе данных, но не избавляет вас от оповещения, которое показано выше.
Действия, которые вы будете принимать далее, зависят только от вас, одним из вариантов есть заказ лицензий на использование MS SQL Server.
Вопрос: есть ли какая-то объективная причина того, что в БД террасофта ни в одной таблице абсолютно не используются кластерные индексы?
У нас система еле шевелится, при том что очень мощный сервер БД, всего около 150 пользователей, таблицы не сказать что очень огромные (десятки-сотни тыс. записей)... кроме таблиц логов (миллионы-десятки миллионов записей) :)
В общем производительность очень низкая.
В рамках нашего проекта вопрос построения индексов либо не был запланирован вообще либо был проигнорирован... Единственные индексы, которые построены - некластерные индексы по внешним ключам и по первичному ключу.
Здравствуйте,
Так сложилось исторически, что для для MSSQL 2000 в общем случае некластерный индекс является оптимальным, так как в Terraosft 3.X для первичных ключей и внешних ключей используются GUID. В этом случае, если включить кластерные индексы, они будут постоянно перестраиваться, т.к. при вставке записей мы всегда получаем случайное значение GUID и для сохранения упорядоченного вида, новую запись нужно вставить в середину индекса.
Для MSSQL 2008, при использовании последовательных GUID, кластерный индекс будет более производительным. В новых версиях мы проанализируем возможность использования таких индексов для MSSQL 2008.
А как на счет использования "разреженных" индексов, в которых FillFactor < 100 (например 60-80)?
Или использование NEWSEQUENTIALID() вместо NEWID()?
Или введения кластерного индекса не связанного с первичным ключем (например, введение поля типа BigInt с автоинкрементом, либо выделение группы полей по которым возможно построить уникальный индекс, например для контрагента - дата создания, наименование, + может быть ИНН, ОГРН)?
Не проводились ли исследования в этой области? Перед тем как начать самому исследование, хотелось бы услышать какие-то рекомендации, наработки, если таковые имеются.
Дело в том что производительность запросов к БД - действительно "больной" вопрос - тут же блокировка таблиц, которая приводит к возникновению дедлоков в случае "тяжелых" запросов, что отчасти на мой взгляд связано с высокой степенью нормализации и недостаточной индексированностью таблиц, т.к. некластерных индексов по внешним ключам явно нехватает...
Тут же возможно возникнут вопросы по сбору статистики для полей как входящих в индексы так и не входящих в них.
Здравствуйте,
1) Генерация самих GUID в Terrasoft 3.X происходит на уровне приложения (используется внутренний генератор Connector.GenGUID()), это дает возможность использовать значения идентификаторов, до их фактической вставки в таблицу, для того что бы использовать последовательную генерацию идентификаторов, необходимо править бинарные файлы, и менять логику построения на генерацию последовательных идентификаторов.
2) Если Вы имеете в виду, замену uniqueidentifier на BigInt, в Terrasoft в качестве первичных ключей, то боюсь Вас разочаровать, многие вещи в конфигурации заточены под использования типа GUID.
В качестве оптимизации вы можете построить группы полей, по которым чаще всего проводиться фильтрация/поиск, и создать кластерный индекс, это действительно может повысить производительность
Последовательные GUID в нашем случае также противоречат репликации – т.к. ключи могут повторяться.
"Яворский Алексей" написал: Яворский Алексей 2 апреля 2012 – 15:48
Здравствуйте,
Так сложилось исторически, что для для MSSQL 2000 в общем случае некластерный индекс является оптимальным, так как в Terraosft 3.X для первичных ключей и внешних ключей используются GUID. В этом случае, если включить кластерные индексы, они будут постоянно перестраиваться, т.к. при вставке записей мы всегда получаем случайное значение GUID и для сохранения упорядоченного вида, новую запись нужно вставить в середину индекса.
Тоесть Вы хотите сказать, что Table Scan будет быстрее работать на наблице в 50к записей, чем Clustered Index Scan???
И что RID Lookup работает быстрее, чем Key lookup при использовании индексов???
И таблица с Identity колонкой и кластерным индексом по ней и Nonclustered Primary Key будет работать медленней, чем таблица без кластерного идекса???
Универсальное решение тяжело найти, с учетом того что система работает и под FB и Oracle. Не всегда большое кол-во индексов способствует повышению производительности, иногда производительность резко падает из-за переизбытка индексов. Если вы используете MS SQL 2008, то в нем есть хороший инструмент под названием "Мониторинг ресурсов". Он Вам покажет что происходит с диком, процессором и какие тяжелые запросы. На комьюнити выкладывались так же запросы по рекомендациям использования индексов (какие лишниеи каких не хватает). Так же не забывайте каждый день (точнее ночь) перестраивать индексы, чистить кэш (SQL-ный) и собирать статистику.
Евгений, я знаю, что избыток индексов - тоже плохо, я также знаю, что GUID в качестве кластерного индекса тоже плохо, т.к. он быстро фрагментируется.
Я также понимаю, что GUIDы удобнее для разработчиков.
Про мониторинг ресурсов, профайлер, чистку кэша, обновление статистик и др тоже хорошо знаю.
В оптимизации запросов тоже не новичок...
Если вы мне покажете хоть один(!) запрос из нескольких таблиц где записей больше 100 и он будет работать быстрее без кластерных индексов (конечно не по гуиду) я успокоюсь :smile:
Михаил, я не в коем случае не хотел Вас уличить в некомпетентности. Просто я сейчас поддерживаю две крупные базы, каждая из которых примерно 60 Гб. Одна на Oracle, вторая на MS SQL 2008R2. Ни на одной нет кластерных индексов, это не заслуга, просто так исторически сложилось. Сервера работаю в штатном режиме и не особо напрягаются (я не имею ввиду те ситуации когда процесятся OLAP кубы :lol:, но это не часто и не долго). Так вот, основные тормоза идут на конечных рабочих местах при открытии разделов и экранных форм, т.к. ОЧЕНЬ много логики и ОЧЕНЬ много полей, что очень сильно замедляет билдинг и рендеринг клиентского приложения в целом.
"Домброва Михаил" написал:Если вы мне покажете хоть один(!) запрос из нескольких таблиц где записей больше 100 и он будет работать быстрее без кластерных индексов (конечно не по гуиду) я успокоюсь
Такого сравнения не делал. То что он буде работать не медленнее - это точно, но пока обхожусь без него.
Кто знает, может этот момент уже близок, и нужно обязательно переходить на кластерный индекс...
Только начинаю работать с системой. Разбираюсь с разработкой печатных форм. Встал вопрос, как понять в какой таблице и в каком поле хранятся нужные мне данные? Смотрел руководства, SDK. Нигде не нашел.
К сожалению, на текущий момент нет руководства с описанием структуры базы данных и таблиц Terrasoft. Но, если у Вас возникнут конкретные вопросы, где хранятся те или иные данные, мы, в рамках технической поддержки, обязательно Вам подскажем.
Инна Безверхняя,
II линия службы поддержки Terrasoft
Здесь просто нужно понимать общую структуру расположения сервисов в дереве в администраторе, это поможет находить нужную вам информацию.
Обычно в верхней иерархии идут разделы (названия на английском):
По названиям разделов вы можете определить где находятся нужные вам таблицы в зависиомости от того, к какому разделу они относятся.
Далее идут подгруппы:
- Detail
Здесь хранятся все сервисы, связанные с деталями раздела
- Dictionaries
Здесь хранятся все сервисы, связанные со справочниками раздела
- General
Здесь находятся сервисы, которые отвечают за отображения основного реестра записей раздела
- Graphs - графики
- Library - библиотека специфичных для этого раздела сервисов
- Reports - различные сервисы, связанные с отчетами FastReport
- User Fields - сервисы, связанные с пользовательскими полями
После того, как вы нашли сервис нужной вам таблицы, открываете этот сервис и слева вы увидите список полей таблицы:
Я могу в чем-то ошибаться, но общее представление у меня такое.
Здравствуйте, Андрей!
Спасибо за Ваш ответ, да, в целом все верно.
Вениамин, хотелось бы еще добавить, что помимо того, что структура сервисов в TS Admin довольно однотипна для всех разделов, структура таблиц в самой БД также довольно прозрачна и, если можно так сказать, интуитивно понятна.
То есть, для каждого раздела есть основная таблица, на примере раздела "Контрагенты" - tbl_Account, далее, вся связанная информация, которая заносится через детали этого раздела хранится в таблицах, которые начинаются с названия раздела + название детали, то есть tbl_AccountAddressess - адреса контрагентов, tbl_AccountCommunications - средства связи контрагентов и т.д., аналогично справочная информация по данному разделу tbl_AccountType - типы контрагентов и т.д.
По тому же принципу хранится информация о группах записей и правах доступа к записям: tbl_AccountGroup и tbl_AccountRight.
По такому принципу хранится информация из всех разделов со всеми соответствующими связями.
Ну и, конечно, служебные таблицы, такие как, например, tbl_DatabaseInfo, в которой Вы можете посмотреть информацию о версии базы, кешировании сервисов и прочее.
Это в общих чертах, подробнее будем рады ответить на более конкретные вопросы.
Инна Безверхняя,
II линия службы поддержки Terrasoft
Вениамин, для более углубленного анализа (уже для этапа программирования конфигурации) могу порекоммендовать SDK, в котором Вы сможете найти описание свойств и методов для используемых в системе интерфейсов.
А вот по какому принципу хранится информация в табличке tbl_Service ? Особенно блоб "XMLData".
В каком виде хранятся тексты "сервисов" ? Ну точно не в виде чистого XML.
Насколько я понял из приведённого топика - XML-сериализация производится при выгрузке сервиса (модуля) в текстовый файл. При загрузке - XML-десериализация. А вот на стадии записи в БД выполняется маршалинг (сохранение всего объекта, включая программу, данные и метаданные). Попросту вся область памяти объекта (сервиса) выгружается в BLOB. Или я ошибаюсь?
Вопрос простой - как просмотреть/отредактировать модуль (сервис) во внешнем приложении имея доступ к БД? IBExpert воспринимает обсуждаемый BLOB как двоичный (это естественно при неизвестной структуре).
Для редактирование сервиса из БД необходимо:
1.Получить значение BLOB-поля
2.Разархировать его – получится XML сервиса
3.Редактировать текст XML
4.Заархивировать
5.Записать заархивированный XML в то же поле
Но редактирование XML на прямую может повлечь ошибки. Если сервис неправильно отредактирован и записан в БД, он станет недоступным для редактирования в TSAdmin и для использования в TSClient, т.к. он не сможет правильно дисериализироваться.
Для решения Вашей задачи лучше работать с сервисами через COM-объекты Terrasoft из любого внешнего приложения:
1.Например, запросить сервис sq_Contact (Services.GetNewItemByUSI)
2.Модифицировать его как угодно, добавлять колонки, фильтры, union’ы и т.д. – это минимизирует ошибки, т.к. COM-объекты Terraosft делают проверку возможности тех или иных изменений. А работа напрямую с текстом XML ничего не проверяет
3.И после модификаций сохранить Services.SaveItem(Service, sdoaSave) в БД
Здравствуйте.
На текущий момент готового руководства с описанием структуры базы данных и таблиц Terrasoft CRM 3.3.2 нет. Но если у Вас есть конкретные вопросы - задавайте и мы в рамках технической поддержки Вам ответим.
Terrasoft Support Team.
Ну это вопрос другой, было бы проще получить описание.. У меня пользователи как бы должны сами научиться пользоваться CRM - там ведь все просто ;) - приходиться писать краткие мануалы по той или иной задаче.
Решил обобщить немного информации о том, какие действия чаще-всего требуется выполнять при перенесении базы данных Terrasoft для СУБД MS SQL. Также хотелось бы ответить на часто задаваемый пользователями вопрос: переносить базу данных без проблем можно либо на SQL сервер той-же версии, либо версии старше (т.е. с MS SQL 2005 на MS SQL 2008 база данных может быть перенесена, наоборот же, с более новой версии на более старую, перенос базы данных не подразумевается).
Итак, при переносе базы данных с сервера на сервер выполняется следующая последовательность действий:
Необходимо сделать бэкап базы данных на одном сервере и восстановите его на втором.
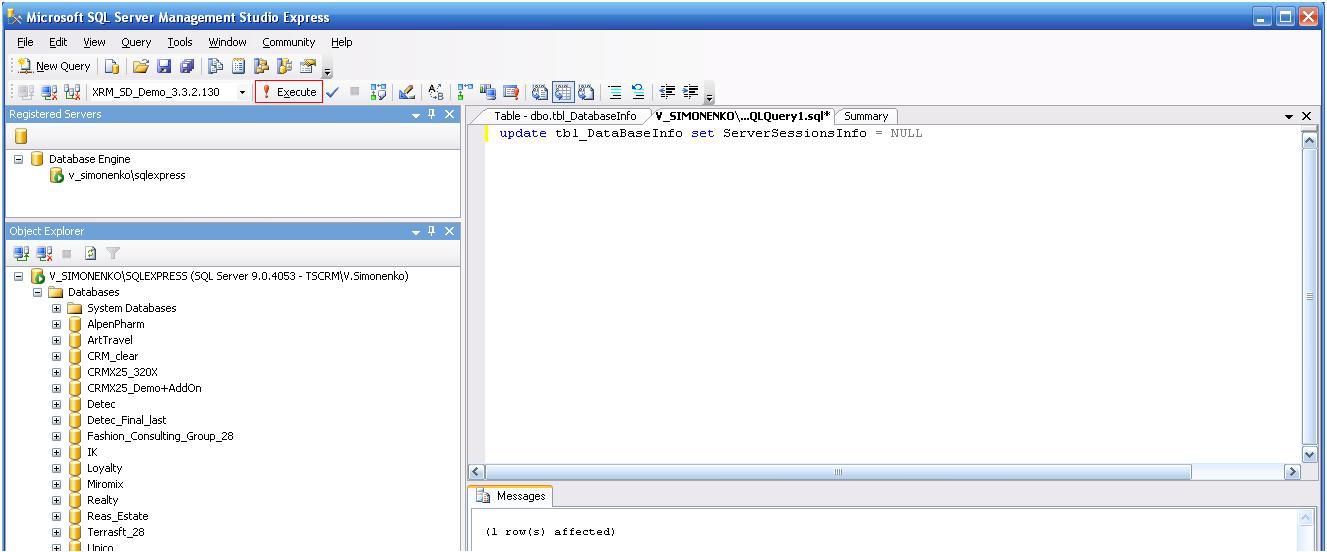
Если использовались конкурентные лицензии, то в первую очередь очистите значение сервера сессий для базы данных. Сделать это можно с помощью следующего запроса к базе данных: update tbl_DataBaseInfo set ServerSessionsInfo = NULL
Для выполнения запроса сделайте следующее:
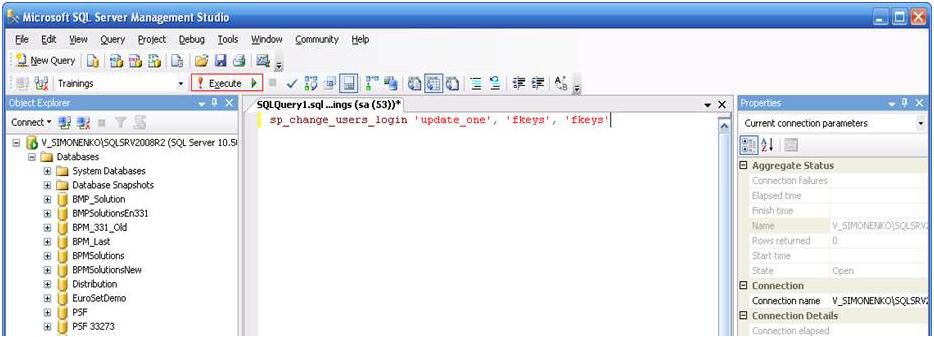
Вызовите контекстное меню, нажав правой кнопкой мыши на названии базы данных, и выбрать New Query.
Далее ввести запрос и нажать Execute для его выполнения.
После этого Вам необходимо будет перезаказать конкурентные лицензии.
Также при переносе базы данных на другой сервер необходимо производить сопоставление пользователей базы данных Terrasoft с именами входа в MS SQL.
Предварительно необходимо создать соответствующие имена входа на SQL сервере.
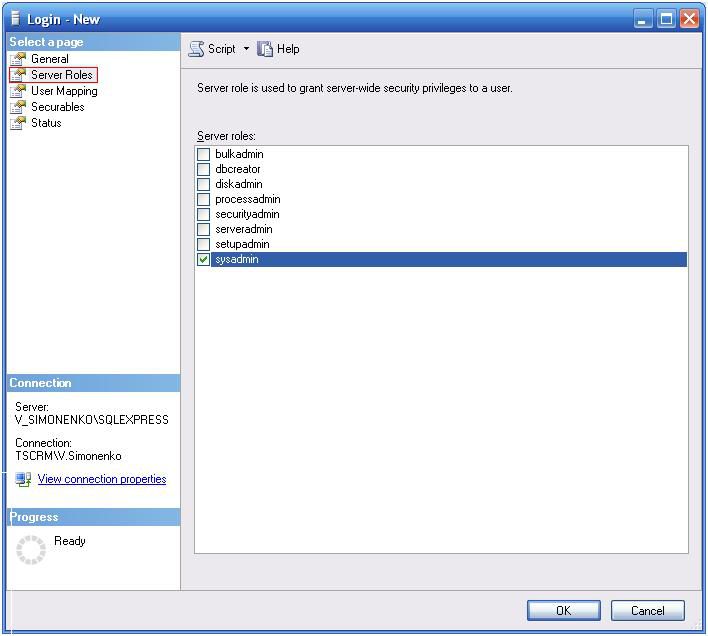
Для этого на сервере необходимо перейти во вкладку [Security]>[Logins] и там создать соответствующие имена входа.
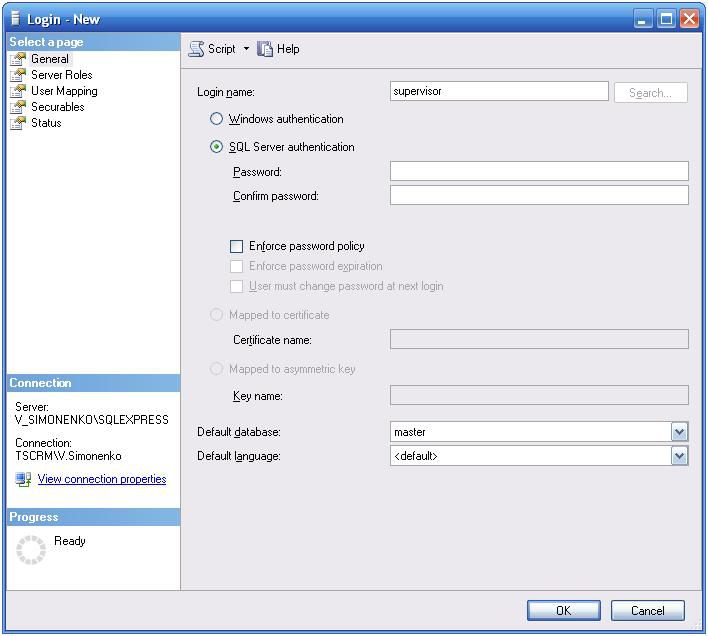
Обязательно при создании имени входа для пользователя указать тип авторизации – «SQL аторизация»:
Также обязательным условием является установка серверной роли «сисадмин» для имени входа системного администратора Terrasoft.
Далее необходимо провести, собственно, сопоставление. Сделать это можно выполнив запрос к базе данных следующего рода:
sp_change_users_login 'update_one', 'fkeys', 'fkeys'
Данный запрос необходимо выполнить для каждого пользователя Terrasoft заменив в запросе слово “fkeys” на соответственное (например для supervisor’a данный запрос примет вид sp_change_users_login 'update_one', 'supervisor', 'supervisor').
Далее, если предполагается перенос базы данных в другой домен (следовательно, и пользователи с домена изменятся) для изменения пользователей Вам необходимо выполнить следующий порядок действий:
1. В таблице tbl_AdminUnit базы данных Terrasoft в полях .Name и .SQLObjectName заменить соответствующие записи пользователей из старого домена на новые. Например если пользователь раньше имел имя tm/Yakovenko (домен tm), а стал tcrm/Yakovenko (домен tscrm), то записи в указанных полях Вы должны заменить на tcrm/Yakovenko.
2. Создать login (подтянуть из Active Directory).
3. Добавить пользователя в БД с новым логином.
4. Если пользователь имел роль системного администратора в Terrasoft, то его логину необходимо дать роль sysadmin.
5. Если пользователь имел роль обычного администратора в Terrasoft, то его логину необходимо дать роль dbowner.
6. После этого в Terrasoft в разделе [Администрирование] каждому пользователю на детали [Группы] необходимо удалить и добавить все группы (таким образом пользователю перераздадутся права доступа).
Переносил Terrsfoft XRM 3.3.2 в новый Win 2008 домен.
Вот скрипты шагов 1-5, описанных Владом для MS SQL Server 2008 R2.
-- восстановили БД
RESTORE DATABASE [TSXRM] FROM DISK ='c:\TSXRM.BAK'
GO
--подключаемся к восстановленной БД
USE TSXRM
GO
--пересвязываем системного юзера
EXEC sp_change_users_login 'update_one', 'fkeys', 'fkeys'
GO
-- создаем заново имена входа (проверяем не существует ли уже такое имя входа,
-- чтобы можно было запускать скрипт многократно)
IF NOT EXISTS (SELECT * FROM sys.server_principals WHERE name = N'SQLServerAuthLoginName')
CREATE LOGIN [SQLServerAuthLoginName] WITH password ='123456', DEFAULT_DATABASE =[TSXRM], DEFAULT_LANGUAGE=[русский]
go
-- пересвязываем созданные sqlserver`ные имена входа с пользователями
EXEC sp_change_users_login @action ='update_one', @UserNamePattern ='SQLServerAuthUserName', @LoginName ='SQLServerAuthLoginName'
GO
-- создаем NT`ные (виндовые, доменные) имена входа
IF NOT EXISTS (SELECT * FROM sys.server_principals WHERE name = N'MyNewDomainName\TSAdminUserName')
CREATE LOGIN [MyNewDomainName\TSAdminUserName] FROM WINDOWS WITH DEFAULT_DATABASE=[TSXRM], DEFAULT_LANGUAGE=[русский]--добавляем в группу db_owner, если юзер есть админ в TS
EXEC sys.sp_addrolemember @rolename ='db_owner', @membername = N'MyNewDomainName\TSAdminUserName'--создаем пользователя для имени входа (создание собственной схемы вроде не нужно)--CREATE SCHEMA [MyNewDomainName\TSAdminUserName] AUTHORIZATION [MyNewDomainName\TSAdminUserName]
IF NOT EXISTS (SELECT * FROM sys.database_principals WHERE name = N'MyNewDomainName\TSAdminUserName')
CREATE USER [MyNewDomainName\TSAdminUserName] FOR LOGIN [MyNewDomainName\TSAdminUserName]-- WITH DEFAULT_SCHEMA=[MyNewDomainName\TSAdminUserName]--удаляем старых пользователей (сначала удалив собственную схему)
IF EXISTS (SELECT * FROM sys.database_principals WHERE name = N'OldDomainName\TSAdminUserName')
BEGIN
DROP schema [OldDomainName\TSAdminUserName]
DROP USER [OldDomainName\TSAdminUserName]
END
GO
--правим имя домена в таблице AdminUnit
DECLARE @OldDomainName AS NVARCHAR(255)
DECLARE @NewDomainName AS NVARCHAR(255)
SET @OldDomainName = N'OldDomainName'
SET @NewDomainName = N'MyNewDomainName'
UPDATE
[tbl_AdminUnit]
SET
Name = REPLACE([Name], @OldDomainName, @NewDomainName),
SQLObjectName = REPLACE([SQLObjectName], @OldDomainName, @NewDomainName)
WHERE
IsDomainUnit =1
Интересно, если бы перенос был на MS SQL Server 2012, получилось бы сделать БД Terrasoft contained database, дабы избежать необходимости отдельного переноса имен входа?
Здравствуйте.
При создании пользователя в базе данных он автоматически дублируется логином на уровне СУБД. Если Вы перенесёте базу на другой SQl-сервер, пользователи вместе с базой перенесутся, а логины, соответственно - нет. Их нужно будет создавать в ручном режиме и связывать с пользователями "хранимкой" sp_change_users_login. Если пользователей очень много, то можно пробовать это выполнять путём переноса\модификации системной базы master. Протестированного механизма - нет. Всё же рекомендую выполнить сопоставление логинов через процедуру.
С уважением, Terrasoft Support Team.
Александр, особенность contained database в том, что они включают в себя такие объекты уровня сервера, как например, имена входа (логины). Эта возможность появилась в MS SQL Server 2012.
Другое дело, что не каждая легаси-БД с прежней версии сервера может быть приведена к виду contained database.
Как раз в этом и была суть моей мысли - может ли база TS приведена к такому виду.
"Msg 15291, Level 16, State 1, Procedure sp_change_users_login, Line 114
Terminating this procedure. The User name 'fkeys' is absent or invalid".
Читал вот здесь: http://www.community.terrasoft.ru/forum/topic/6775 , что причина может крыться в недостатке прав юзера, из под которого мы пытаемся его выполнить, однако, я это пробовал делать даже из под "sa".
Раньше каким-то чудом на другой машине умудрился восстановить бэкап master. Сейчас такой фокус не проходит (после восстановления сервер не стартует), а при ручном добавлении логинов, появляется проблема описанная выше.
Переносим тестовую базу на другой сервер. Работаем по конкурентным лицензиям,
Terrasoft Sales, версия 3.3.2.47
MSSQL 2010
При попытке адмнов перенести логины все сразу, появляется сообщение
The database 'Terrasoft332_Sales' does not exist. Supply a valid database name. To see available databases, use sys.databases.
'Terrasoft332_Sales' - это название боевой базы, с которой берутся лицензии для тестовой. Подскажиет пожалуйста, в чем может быть проблема?
Здравствуйте. Каким образом переносили все логины сразу? Они содержатся в системной базе "master". Можно попробовать выполнить это путём преноса базы "master", но процедура довольно нетипиная, лежит исключительно в области администрирования СУБД и требует тестирования. Дело в том, что манипуляции с системными легко могут повредить сам SQL-сервер. Гораздо проще логины создать в ручном режиме. После переноса базы с конкурентными лицензиями их необходимо будет перезаказать. Так же, если использовался сервер сессий, то он должен быть доступен для нового сервера БД.
Последний раз я так как Вы сказали я и сделал, всё получилось. А перенести "master" первый раз удалось, действительно задача, прямо скажем: мягко говоря нетривиальная, это удалось сделать в сингл-юзер режиме под пользователем "sa" из консоли. Больше я этим заниматься желанием не горю
Почему в статье самое главное не указывается, т.е. если информацию по собственно переносу базы можно найти без проблем в открытых источниках, то я лично застрял на совершенно глупом на мой взгляд шаге, и фича чисто террасофтовская - изменить строку соединения сервера сессий конкурентных лицензий.
Два дня убил на поиски проблемы почему у меня база после переноса с сервера А на сервер B все равно смотрит на сервак А. Выяснял этот факт тоже опытным путем - гашу инстанцию на сервере А после переноса (что бы пользователи не имели доступа к старой базе не при каких обстоятельствах) нет коннекта к новой базе на сервере B - ошибка - отсутствует доступ к базе, периодически ошибка сменялась на отсутствие доступа из под логина. Первоначально грешил на соответственно на логины - и скрипт c update_one затер просто до дыр.
Запускаю сервис MS SQL на старой могу заходить в новую базу. Netstat-ом выяснил, что есть обращения с B на A, но по какой причине - не было понятно.
Совершенно случайно, когда стало окончательно понятно, что проблема не на стороне SQL и логинов в базе master, я начал перебирать уже все, что можно настраивать на стороне 3ки, так я и набрел на эту настройку.
Переезд базы задача не повседненвная и держать настройки в голове по сервису конкурентных лицензий вообще не получается. Странно что эти грабли нигде не описаны.
На 2005 запустил системную процедуру sp_help_revlogin, исходник которой есть на просторах интернета. Она выдаёт готовый скрипт на создание имён входа. Подчистил скрипт, чтобы он не пересоздал уже имеющиеся системные логины, типа SA и т.п.
Запустил этот скрипт на 2012. Все имена входа создались. Самое главное, что их ID, роли и права абсолютно идентичны старому серверу.
Предыдущие два пункта выполняются под пользователем, имеющем достаточные права к базе master. Лучше под sa.
При запуске ServiceDesk создал новую конфигурацию, указав новый сервер. Заход под пользователем с именной лицензией прошел сразу. Под конкурентными лицензиями не пускало.
Из мененджера лицензий штатно создаю запрос, получаю ответ, загружаю. И всё работает.
Добрый день. Подскажите как выбрать данные из другой базы данных например Oracle, когда основная база на MySQL
Создаем ADOConnection, ADOCommand, ADODataset. Тест подключения проходит нормально...
Здравствуйте.
Если тест проходит, то это значит, что параметры подключения заданы корректно и тестовая связь проходит успешно. Далее, исходя из поставленной задачи, используя ADOCommand, ADODataset и т. д. реализовываете логику. Обращаю Ваше внимание на то, что желательно использовать ODBC-драйвер от компании Oracle, а не стандарный от Microsoft, который встроен в Windows (там возникает ряд проблем при передаче параметров).
Terrasoft Support Team.
Добрый день! Подскажите пожалуйста, как можно менее проблематично перенести базу данных на Firebird с версий 3.2.0 на 3.3.2 (Terrasoft)
Заранее спасибо!
Под SQL есть альтернатива - переносим доработки руками в виде сервисов или вновь внося изменения, а затем данные перебрасываем с помощью Red Gate. Но вот аналога этой утилиты для firebird я не знаю...
С помощью пакетов перехода между версиями, которые Вам были предоставлены службой технической поддержки, переносятся как данные, так и внесенные изменения при условии успешного разрешения конфиликтов между базовой и доработанной конфигурациями. Таким образом, если у Вас есть все необходимые пакеты перехода, никаких дополнительных манипуляций Вам производить не нужно.
Здравствуйте!
При применении приоритета пакета перехода все конфликтные сервисы заменяются на базовые новой версии, что само по себе не совсем корректно. Таким образом, если Вы обновляете конфигурацию с применением приоритета пакета, то все изменения, внесенные в конфигурацию, будут перезатерты.
По всей видимости, при ручном слиянии сервисов Вы не совсем корректно это сделали, в результате чего окно было перенесено, а поля нет.
Советую Вам попытаться провести обновление и при этом проводить слияние сервисов вручную.
Скорее всего при переходе что-то было неправильно сделано.
Попробуйте сделать все с начала и если ошибка останется - посмотрите в TSAdmin почему не отображаются эти поля (не перенесен сервис, названия полей пустые, неправильное окно и т.д.), тогда станет ясно почему возникает данная ошибка.
Добрый день! Подскажите пожалуйста как просмотреть на что(какие таблицы) распределяется размер базы.
Есть БД размер которой достиг 13Гб(не учитывая журнал транзакций), как быстро оперативно вычислить что именно предает такой вес?
Заранее спасибо!
Выполняем и видим что сколько занимает
+ посмотрите размер файла лога в свойствах самой базы
DECLARE @pagesizeKB int
SELECT @pagesizeKB = low /1024 FROM master.dbo.spt_values
WHERE number =1 AND type ='E'
SELECT
table_name = OBJECT_NAME(o.id),
rows = i1.rowcnt,
reservedKB =(ISNULL(SUM(i1.reserved), 0)+ ISNULL(SUM(i2.reserved), 0))* @pagesizeKB,
dataKB =(ISNULL(SUM(i1.dpages), 0)+ ISNULL(SUM(i2.used), 0))* @pagesizeKB,
index_sizeKB =((ISNULL(SUM(i1.used), 0)+ ISNULL(SUM(i2.used), 0))-(ISNULL(SUM(i1.dpages), 0)+ ISNULL(SUM(i2.used), 0)))* @pagesizeKB,
unusedKB =((ISNULL(SUM(i1.reserved), 0)+ ISNULL(SUM(i2.reserved), 0))-(ISNULL(SUM(i1.used), 0)+ ISNULL(SUM(i2.used), 0)))* @pagesizeKB
FROM sysobjects o
LEFT OUTER JOIN sysindexes i1 ON i1.id= o.id AND i1.indid<2
LEFT OUTER JOIN sysindexes i2 ON i2.id= o.id AND i2.indid=255
WHERE OBJECTPROPERTY(o.id, N'IsUserTable')=1--same as: o.xtype='IsView'
OR (OBJECTPROPERTY(o.id, N'IsView')=1 AND OBJECTPROPERTY(o.id, N'IsIndexed')=1)
GROUP BY o.id, i1.rowcnt
ORDER BY 3 DESC
select t.name as TableName, SUM(u.total_pages)*8/1024 as SizeMB
from sys.tables as t
inner join sys.partitions as p on t.object_id= p.object_id
inner join sys.allocation_units as u on p.partition_id= u.container_id
group by t.name
order by SizeMB DESC